Complete Guide to AI Agent Memory: From Flat Files to Enterprise RAG


26 years building and operating hosting infrastructure. Founded Remsys, a 60-person team that provided 24/7 server management to hosting providers and data centers worldwide. Built and ran dedicated server and VPS hosting companies. Agento applies that operational experience to AI agent hosting.
Table of Contents
An AI agent without memory is just a chatbot with extra steps.
Every conversation starts from zero. "What's my timezone again?" "Remind me what project we discussed yesterday?" "I already told you I prefer TypeScript." Without persistent memory, agents can't learn, can't personalize, and can't build the context that makes them genuinely useful.
Memory is what separates a helpful assistant from a frustrating one. It's also one of the most fragmented parts of the AI agent ecosystem: flat files, SQLite databases, vector search, knowledge graphs, managed APIs, and a growing list of startups all claiming to solve the problem differently.
This guide makes sense of it all. We'll cover OpenClaw's native memory system in depth, explore external memory products like Supermemory, Mem0, Zep, and Letta, and help you decide which approach fits your needs.
The Three Types of Agent Memory
Before diving into implementations, let's establish what "memory" actually means for AI agents:

Short-term (Session) Memory
This is the current conversation context, what's been said in this session. It lives in the LLM's context window and disappears when the session ends. Every agent has this by default; it's not really "memory" in the persistent sense.
Long-term (Persistent) Memory
Facts, preferences, and learned context that survive across sessions. "User prefers TypeScript." "Main project is Retently." "Timezone is UTC+7." This requires explicit storage: files, databases, or external APIs.
Episodic Memory
What happened and when. "Last Tuesday you mentioned wanting to refactor the auth system." "Three weeks ago we discussed switching to Postgres." This requires timestamps and temporal retrieval, knowing not just what but when.
Most agents start with only short-term memory. The goal is adding long-term and episodic layers without drowning in infrastructure complexity.
OpenClaw's Native Memory System
OpenClaw uses a multi-layer architecture that combines plain-text files as the source of truth with SQLite indexing and hybrid search. It's thoughtfully designed and works well for most personal agent use cases.
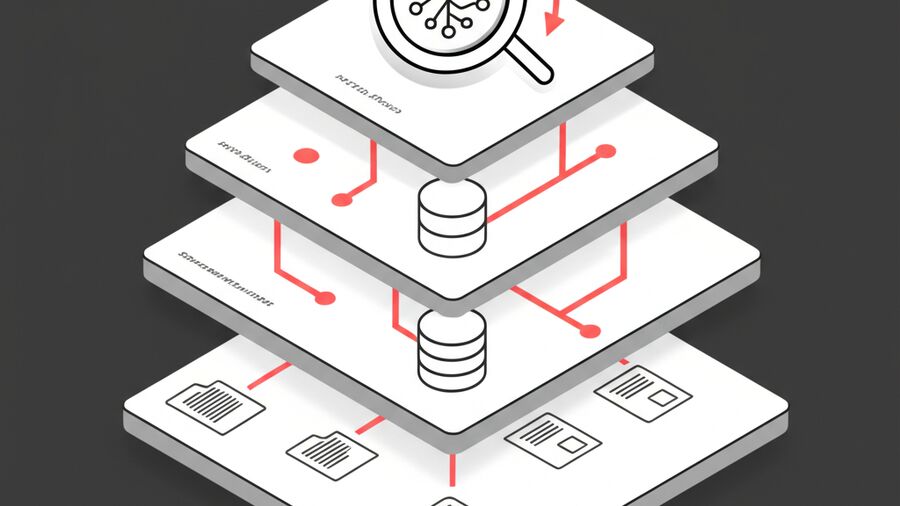
Layer 1: Flat Files (Source of Truth)
~/bot/
├── MEMORY.md # Curated long-term facts
└── memory/
├── 2026-02-01.md # Today's log
└── 2026-01-31.md # Yesterday's log
The filesystem is canonical storage. Everything else is derived from these files.
MEMORY.md holds curated, stable facts that are worth keeping in context frequently. It's only loaded in private sessions (never in group chats where context would be inappropriate). Think of it as your agent's permanent knowledge base about you.
Daily logs (memory/YYYY-MM-DD.md) are append-only files capturing day-to-day context. Today's and yesterday's logs are loaded at session start, giving your agent a rolling 48-hour window of detailed memory. These are git-friendly and human-editable.
The key principle: "The model only remembers what gets written to disk." Memory isn't kept in RAM across sessions. If it matters, it needs to be in a file.
Layer 2: SQLite Indexing Database
The SQLite database at ~/.openclaw/memory/<agentId>.sqlite is a derived store, always rebuildable from the markdown files. It contains:
- files: Tracks memory files with path, hash, and modification time
- chunks: Indexed content split into ~400-token segments with 80-token overlap
- chunks_vec: Vector embeddings for semantic search (via sqlite-vec extension)
- chunks_fts: Full-text search index with BM25 ranking
Chunking preserves line numbers, so search results can point back to exact locations in source files.
Layer 3: Hybrid Search (Vector + BM25)
This is where OpenClaw gets clever. Pure vector search is great for semantic matching ("Mac gateway" finds "the machine running the gateway") but weak on exact tokens (error codes, function names, IDs). Pure keyword search is the opposite.
OpenClaw combines both:
- Vector search returns top candidates by cosine similarity
- BM25 returns top candidates by keyword relevance
- Results merge:
finalScore = 0.7 × vectorScore + 0.3 × textScore - Top 6 results above 0.35 confidence are returned
The blend is configurable, but the defaults work well for most use cases.
Embedding Providers
OpenClaw supports multiple embedding providers with automatic fallback:
| Provider | Model | Notes |
|---|---|---|
| OpenAI | text-embedding-3-small | Default if API key available |
| Gemini | gemini-embedding-001 | Alternative cloud option |
| Local | embeddinggemma-300M | ~600MB download, fully offline |
The fallback chain tries providers in order until one works. This means your agent can function completely offline with local embeddings, or use faster cloud embeddings when available.
Automatic Memory Flush
Before context compaction (when the conversation gets too long), OpenClaw triggers a silent prompt: "Session nearing compaction. Store durable memories now."
This ensures important context gets written to disk before the context window is pruned. It's a safety net so memories aren't lost just because a conversation ran long.
OpenClaw Memory Tools
Agents interact with memory through two tools:
memory_search performs semantic search across all memory files:
memory_search("what hosting provider did we discuss?")
→ Returns chunks with file path, line numbers, confidence score
memory_get reads specific memory files:
memory_get("memory/2026-02-01.md", from=10, lines=20)
→ Returns exact content for follow-up reading
The typical flow: search finds relevant chunks, then get retrieves full context around the matches.
From the command line:
openclaw memory status --deep # Check index health
openclaw memory index # Force reindex
openclaw memory search "query" # Search from terminal
Beyond Native: External Memory Products
OpenClaw's native system works well for personal agents with modest memory requirements. But there are reasons to look beyond it:
- Scale: Native works for ~10k chunks; some use cases need millions
- Cross-agent sharing: Multiple agents accessing shared memory
- Advanced features: Knowledge graphs, temporal reasoning, compression
- Managed infrastructure: Someone else handles embeddings, indexing, backups
Let's look at the major players.
Supermemory
What it is: A universal memory API with a dedicated OpenClaw plugin.
Supermemory has raised $3 million to build "the memory engine for LLMs." Their architecture is inspired by the human brain: forgetting the mundane, emphasizing recent usage, rewriting memories based on current context.
Key features:
- Auto-recall: Queries memory before every AI turn, injecting relevant context
- Auto-capture: Stores conversation content automatically
- User profiles: Builds persistent understanding of each user
- Scale: 50 million tokens per user, 5+ billion tokens processed daily
- Sub-400ms latency: Fast enough for real-time conversation
OpenClaw setup:
openclaw plugins install @supermemory/openclaw-supermemory
# Set SUPERMEMORY_API_KEY in environment
User commands: /remember to store, /recall to retrieve
Best for: Users who want "set and forget" memory that scales beyond native limits. The plugin handles everything automatically, no manual memory curation needed.
Pricing: Requires Pro subscription.
Source: Supermemory | OpenClaw Plugin
QMD (OpenClaw Sidecar)
What it is: A local-first search sidecar built by Tobi Lütke, founder of Shopify.
QMD runs entirely on your machine with no cloud APIs or external calls. It combines BM25 keyword search with vector embeddings and optional reranking, all powered by small GGUF models that auto-download on first use. It's designed as a drop-in upgrade over OpenClaw's built-in SQLite memory backend.
Key features:
- Fully local: All models run on-device, no API keys needed for search
- Hybrid search: BM25 + vector embeddings for both semantic and exact-match retrieval
- Three search modes: Fast hybrid (default), vector-only, or thorough with query expansion and reranking
- Session indexing: Optionally index past conversation transcripts for recall
- Auto-downloads models: GGUF models (~2 GB total) download once and are shared across agents
OpenClaw setup:
bun install -g https://github.com/tobi/qmd
Then in your openclaw.json:
{
"memory": {
"backend": "qmd"
}
}
Best for: Self-hosters who want powerful local search without cloud dependencies. If privacy is non-negotiable and you're comfortable running a sidecar process, QMD is the strongest local option available for OpenClaw.
Pricing: Free, open source.
Mem0
What it is: A self-improving memory layer for LLM applications.
Mem0 uses a hybrid architecture combining vector search, knowledge graphs, and key-value storage. Its core advantage is intelligent memory compression, reducing token usage while preserving context fidelity.
Key features:
- Adaptive memory updates: Memory improves over time
- Multi-level recall: Different retrieval strategies for different needs
- Multi-framework: Works with OpenAI, LangGraph, CrewAI, and more
- Performance: 26% accuracy improvement over baseline, 91% faster response time
Best for: Developers building custom agents who want fine-grained control over memory behavior. Mem0 is more of a building block than a plug-and-play solution.
Zep
What it is: Open-source memory infrastructure for chatbots and agents.
Zep focuses on temporal knowledge graphs and structured session memory. It's designed for teams deploying conversational AI at production scale who need memory to be reliable, queryable, and observable.
Key features:
- Temporal knowledge graphs: Track not just what, but when
- Drop-in integration: Works with LangChain, LangGraph out of the box
- Session management: Structured conversation history
- Performance: 18.5% accuracy improvement, 90% latency reduction
Best for: Teams with complex temporal reasoning needs. If your agent needs to answer "what did we discuss last week about authentication?" with precision, Zep's knowledge graphs help.
Letta (formerly MemGPT)
What it is: An open AI lab pursuing foundational research in agent memory.
Letta's philosophy is distinctive: agents should outlast any single foundation model. Their work on "continual learning in token space" enables agents to carry memories across model generations, which matters as the LLM landscape keeps evolving.
Key features:
- Model-agnostic: Works across different LLMs
- Virtual context management: Efficiently handle context beyond model limits
- Sleep-time compute: Offline learning and memory consolidation
- Open-source: 19K GitHub stars, active community
Products:
- Letta Platform: API for building agents with persistent memory
- Letta Code: Memory-first coding agent (#1 model-agnostic on Terminal-Bench)
Best for: Research-minded developers and teams concerned about model lock-in. If you're building something that needs to survive the next three generations of foundation models, Letta's thinking ahead.
Comparison Table
| Product | Type | Scale | OpenClaw Integration | Best For |
|---|---|---|---|---|
| Native OpenClaw | Files + SQLite | ~10k chunks | Built-in | Simple setups, privacy |
| QMD | Local sidecar | ~10k chunks | Built-in backend | Self-hosters, privacy-first |
| Supermemory | Managed API | 50M tokens/user | Official plugin | Production agents |
| Mem0 | Hybrid layer | Large | Custom integration | Fine-grained control |
| Zep | Knowledge graphs | Large | Custom integration | Temporal reasoning |
| Letta | Research platform | Variable | Custom integration | Model-agnostic needs |
Choosing the Right Memory Solution
Decision Framework
Use OpenClaw native if:
- Single agent for personal use
- Privacy matters (everything stays local)
- You want git-backed, human-readable memory files
- Memory requirements are modest (<10k chunks)
- Offline operation is important
Upgrade to QMD if:
- Self-hosting OpenClaw and want better search than the built-in SQLite backend
- Privacy is non-negotiable and everything stays on your machine
- You have ~2 GB of disk for the local models
- You want reranking and query expansion without cloud APIs
Add Supermemory if:
- You want zero-config persistent memory at scale
- Building production agents for multiple users
- Don't want to manage embedding infrastructure
- Need memory that "just works"
Use Mem0 or Zep if:
- Building custom agents (not necessarily OpenClaw)
- Need fine-grained control over memory behavior
- Already using LangChain/LangGraph ecosystem
- Have backend engineering capacity for integration
Use Letta if:
- Research or experimental projects
- Concerned about model migration/lock-in
- Want open-source foundations
- Building novel memory architectures
The Hidden Complexity
Self-hosting memory infrastructure seems simple until you consider:
- Embedding costs: $0.0001 per 1k tokens sounds cheap until you're reindexing regularly
- Index maintenance: Corruption recovery, schema migrations, reindexing after config changes
- Backup verification: Is your backup script actually working?
- Cross-device sync: Memory on your laptop, agent on a server
- Security: Memory files contain sensitive personal context
These aren't insurmountable problems, but they're real maintenance burden that compounds over time.
Memory on Agento
Agento takes a different approach: we've built our own RAG-based memory system specifically optimized for OpenClaw agents.
What's included (in all plans, at no additional cost):
- Agento Memory: Our own RAG implementation, pre-configured and production-ready
- OpenClaw native memory: Works out of the box, no configuration needed
- Supermemory integration: One-click enable if you want additional capabilities
- Automatic backups: Memory files backed up daily
- Index health monitoring: We detect and fix issues before they affect your agent
- Embedding costs included: No surprise bills for reindexing
You focus on:
- What goes in MEMORY.md
- What your agent should remember
- Your actual work
Memory infrastructure should be invisible. You shouldn't think about embeddings, vector indices, or SQLite corruption. You should think about what your agent knows and how it helps you.
For a deeper look at how the two-step system works under the hood, see our How Agent Memory Works guide.
Best Practices for Agent Memory
Regardless of which system you use, these practices help:
Curate MEMORY.md
- Keep it under 500 lines since it loads into every session
- Structure with clear headers for navigation
- Never store secrets (API keys, passwords, tokens)
- Promote important patterns from daily logs
Let Daily Logs Flow
- Don't over-curate daily logs. They're meant to be raw
- Review weekly, promote lasting insights to MEMORY.md
- Let old logs age out naturally (or archive if needed)
Be Explicit About Memory
The agent can't read your mind about what matters:
- "Remember that I prefer TypeScript over JavaScript"
- "Note this for future reference: deployment is on Vercel"
- "Add to my profile: timezone is UTC+7"
Explicit memory commands work better than hoping the agent infers importance.
Memory Security
Memory files contain personal context, potentially sensitive:
- Back up encrypted, not plain text
- Don't share workspace folders carelessly
- Review what's being captured periodically
- Consider what happens if files are compromised
Conclusion
Memory transforms chatbots into genuine assistants. Without it, every conversation starts from zero. With it, your agent builds understanding over time, knowing your preferences, your projects, your context.
OpenClaw's native memory system is solid for most personal use cases: flat files for durability, SQLite for indexing, hybrid search for retrieval. It's local, private, and git-friendly.
For larger scale or managed convenience, external products like Supermemory, Mem0, Zep, and Letta each bring different strengths. Supermemory offers the smoothest OpenClaw integration. Mem0 and Zep give fine-grained control. Letta thinks long-term about model evolution.
The right choice depends on your needs: personal vs multi-user, local vs cloud, simple vs complex temporal reasoning.
Want memory that just works?
Agento includes our own RAG-based memory system in all plans at no additional cost. No configuration, no maintenance. OpenClaw native memory works out of the box. Supermemory integration is one click away.
Your agent remembers what matters. We handle the infrastructure.
Related reading: